
AI Akademik Makale Krizine ArXiv’den Sert Karar: 1 Yıl Men
Bilimsel araştırmaların dünyadaki en büyük ve en prestijli açık erişim deposu olan ArXiv, son dönemde dijital kültür ve akademi dünyasında tırmanışa geçen AI akademik makale krizine karşı tarihi bir rest çekti. Büyük dil modellerinin (LLM) hayatımıza girmesiyle birlikte bilimsel üretim süreçleri hiç olmadığı kadar hızlansa da bu durum kontrolsüz bir içerik üretimini ve ciddi bir etik krizini de beraberinde getirdi. Yaşanan bu yapay zeka istilasına karşı radikal bir adım atan platform, tamamen yapay zeka tarafından üretilen ve kontrol edilmeyen çalışmaları yükleyen yazarlara 1 yıl boyunca yayın yasağı uygulayacağını duyurdu.
Peki, dijital akademide kartlar yeniden mi dağıtılıyor? Kendi yarattığı teknolojik devrimin merkez üssü olan bir platform, neden yapay zekaya karşı barikat kurma ihtiyacı hissetti?

Bilimsel Yayıncılıkta Yapay Zeka İstisnaları ve Alınan Önlemler
Özellikle bilgisayar bilimi, matematik ve yapay zeka alanlarında devrimsel nitelikteki çalışmaların ilk durağı olan ArXiv, geleneksel akademik dergiler gibi aylarca süren katı hakem heyeti süreçlerine sahip değil. Bilginin hızlı yayılması amacıyla kurulan bu sistem, son dönemde suistimallere açık hale geldi. Akademik unvan kazanmak, yayın sayısını artırmak ya da fon elde etmek isteyen bazı araştırmacıların, hiçbir veri toplamadan veya deney yapmadan tamamen yapay zekaya makale yazdırmaya başladığı görüldü.
ArXiv, düşük kaliteli ve yapay zeka tarafından üretilen makalelerin artan sayısı ile mücadele etmek için zaten adımlar atmıştı. Platform, daha önce bu durumun önüne geçebilmek adına ilk kez makale gönderenlerin tanınmış bir yazardan onay (referans) almasını şart koşmuştu. Ancak alınan bu önlemlere rağmen kontrolsüz üretimin önüne geçilemeyince platform doğrudan ceza sistemine geçme kararı aldı.
Yirmi yılı aşkın süredir Cornell tarafından barındırıldıktan sonra bağımsız bir kar amacı gütmeyen kuruluş haline gelen arXiv, bu yeni yapısı sayesinde yapay zeka kaynaklı "AI slop" (değersiz içerik) gibi sorunları ele almak için daha fazla fon toplayabilecek. İşte bu finansal ve kurumsal güçle birlikte devreye giren yeni ArXiv AI politikası, doğrudan yaptırımlarla bilimsel bilginin güvenilirliğini korumayı hedefliyor.
Bilimsel Dürüstlük Mücadelesi: Neden Şimdi ve Bu Kadar Sert ?
Platform yönetiminin bu radikal adımla hayata geçirdiği yeni politikanın temel hedefleri ise oldukça net:
İnsan denetiminin ve sorumluluğunun korunması:
Yapay zekanın tek başına bir yazar gibi hareket etmesinin önüne geçilmesi hedefleniyor.
Yapay zeka içeriklerinin filtrelenmesi:
Düşük kaliteli veya 'halüsinasyon' (uydurma) içeren verilerin yayılmasının engellenmesi amaçlanıyor.
Akademik literatürün güvenilirliğinin sürdürülmesi:
Dijital platformun küresel saygınlığının korunması öncelik tutuluyor.
Bu karar, sadece bir cezalandırma amacı taşımıyor; aynı zamanda bilimsel topluluğa bir 'sorumluluk' çağrısı amaçlayan adeta bir mesaj veriyor: Yapay zeka araçları birer asistan olabilir ancak son kararı veren ve inisiyatif alan her zaman yazarın kendisi olmalıdır.

Tembelliğe Geçit Yok: "Tek Hata" Kuralı Devrede
Yeni kurallar, yapay zekanın araştırmacılar tarafından bir asistan olarak (dil düzenlemesi, redaksiyon, çeviri veya kod yazımı gibi süreçlerde) kullanılmasına karşı topyekun bir yasak getirmiyor. Platformun asıl üzerinde durduğu nokta, içerik nasıl üretilirse üretilsin yazarların tüm sorumluluğu üstlenmesi. Araştırmacılar, yapay zekadan aldıkları yanıltıcı bilgileri veya uydurma referansları doğrudan çalışmaya eklediklerinde tüm sorumluluğu üstlenmiş olacaklar.
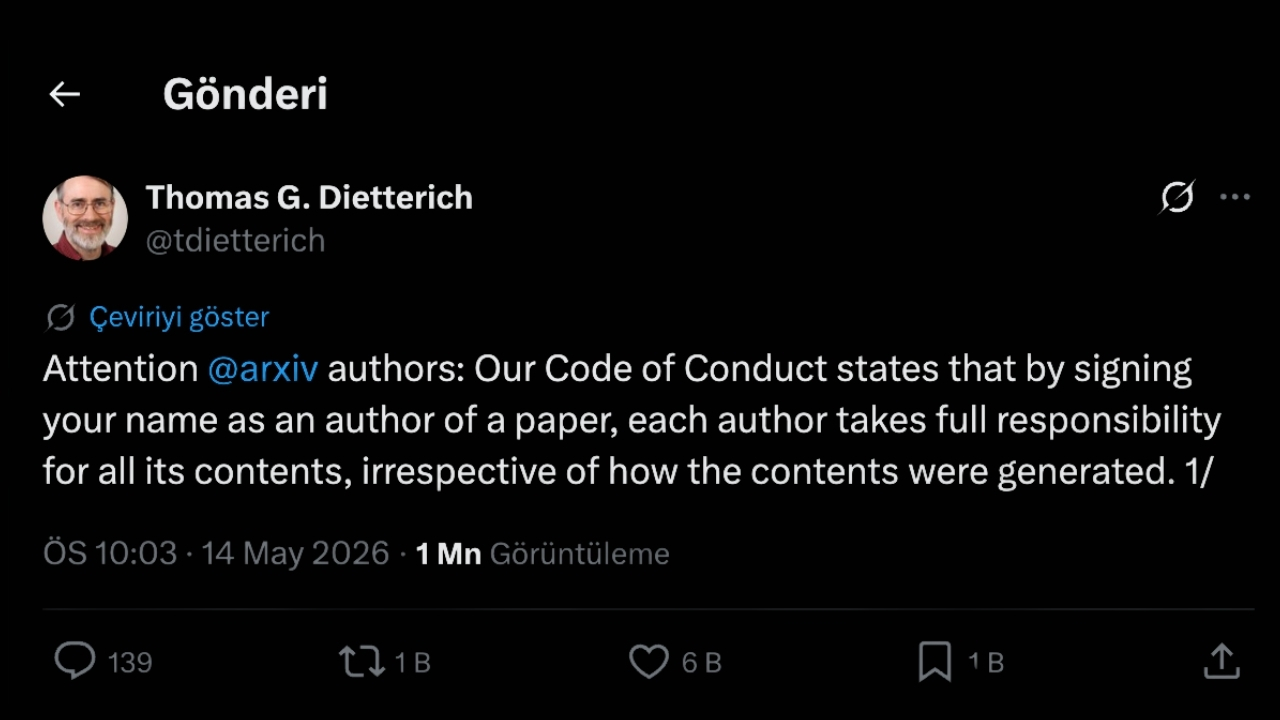
Bu tür durumlar tespit edildiğinde süreç "tek hata" (one-strike) prensibiyle işleyecek. Moderatörlerin raporlaması ve bölüm başkanlarının kanıtları onaylamasının ardından ceza kesinleşecek. Kuralı ihlal eden yazarlar 1 yıllık ArXiv men cezasının yanı sıra, ceza bittikten sonra platforma gönderecekleri yeni makaleleri ancak önceden saygın ve hakemli bir mecrada kabul görmüş olması şartıyla yükleyebilecekler. Yazarların bu kararlara karşı itiraz etme hakkı da saklı tutulacak.
Gelecekte Bizi Ne Bekliyor?
Bu karar, yapay zeka araştırma etiğinin sınırlarını netleştirmek adına büyük bir adım olsa da akademide çok daha büyük ve derin tartışmaların fitilini ateşlemiş durumda. Madalyonun diğer yüzünde, yapay zeka tespit araçlarının (AI detectors) zaman zaman hatalı sonuçlar verebildiği ve tamamen özgün metinleri bile AI üretimi gibi etiketleyebildiği biliniyor. Özellikle ana dili İngilizce olmayan ve yapay zekayı sadece dilsel bir destek aracı olarak kullanan genç araştırmacıların bu katı kurallardan ve tek hatada engellenme riskinden nasıl etkileneceği ise akademide şimdiden büyük bir merak konusu.

Öte yandan, ArXiv’in kurumsal olarak bağımsız bir yapıya bürünmesi ve fon arayışına girmesi, bu tür teknolojik krizlerin sadece kurallarla değil, çok daha büyük bir bütçe ve teknolojik altyapıyla çözüleceğinin de bir göstergesi. Önümüzdeki dönemde sadece makalelerin değil, makaleleri denetleyen sistemlerin de yapay zeka entegrasyonlarını tartışmaya başlayacağız. Bilim dünyası, üretilen içeriğin hızından ziyade doğruluğuna bütçe ayırmak zorunda kalacak gibi gözüküyor.
Sonuç olarak; teknoloji ne kadar gelişirse gelişsin, LLM bilimsel yayın süreçlerinde insanın entelektüel emeği, şüpheciliği ve denetimi olmadan üretilen içerikler bilim dünyasında kabul görmeyecek. ArXiv’in bu hamlesi, dijital kültür ve bilim dünyasının gelecekteki ortak yaşam standartlarını, etik sınırlarını ve en önemlisi “özgün ve doğru bilgi” tanımını yeniden belirleyecek tarihi bir dönüm noktası olmaya aday.
Yorumlar (0)
Yorum yapmak için giriş yapmalısınız.
Giriş Yap