
 Zaman Yönetimi: Zamanı Yönetmek Değil, Hayatı Yöne...
Zaman Yönetimi: Zamanı Yönetmek Değil, Hayatı Yöne...
 Veri Bilimi Eğitimi
Veri Bilimi Eğitimi
 Etkili CV Hazırlama
Etkili CV Hazırlama




Yapay zeka dünyası, Anthropic'in en yeni amiral gemisi modeli Claude Opus 4.5'in piyasaya sürülmesiyle büyük bir dönüşüme tanıklık ediyor. Anthropic, bu modelin sadece zeki ve verimli olmakla kalmayıp, yapay zeka kodlama performansı, ajan sistemleri ve bilgisayar tabanlı görevler için dünyanın en iyi modeli olduğunu iddia ediyor. Bu iddia, OpenAI'ın GPT-5'ini ve Anthropic'in önceki modeli Sonnet 4.5'i geride bırakan benchmark sonuçlarıyla destekleniyor.
Claude Opus 4.5, gerçek dünya yazılım mühendisliği testlerinde gösterdiği üstün başarı ve AI ajan yeteneklerindeki "Waymo anı" benzeri sıçramayla, iş yapış biçimlerini ve mühendislik mesleğini kökten değiştirecek bir öncü olarak konumlanıyor. Bu yazımızda, modelin mimarisini, rakiplerle karşılaştırmasını ve geliştiriciler için sunduğu ekonomik avantajları derinlemesine inceleyeceğiz.
Claude Opus 4.5 Nedir ve Nasıl Bir Atılım Sağladı?
- Nedir ve Ne Zaman Çıktı? Claude Opus 4.5, Anthropic'in en üst düzey, genel amaçlı LLM'sidir ve 1 Kasım 2025 tarihinde API, uygulamalar ve büyük bulut platformları üzerinden erişime açıldı.
- Nasıl Bir Sıçrama Yaptı? Model, belirsizliği ele alma ve karmaşık çok sistemli hataları çözme yeteneğinde önemli bir gelişme gösterdi. Test uzmanlarından gelen geri bildirimler, Opus 4.5'in el yordamına gerek kalmadan (zero-shot) karmaşık görevleri güvenilir bir şekilde tamamlayabildiğini doğruluyor.
- Temel Başarısı: Model, yazılım mühendisliği alanında insan zekasını taklit eden performansıyla, önceki modellere kıyasla "anlamlı bir adım" olarak nitelendiriliyor. Bu durum, AI'ın artık sadece bir asistan değil, bir iş ortağı olarak konumlandığına işaret etmekte.
Kodlama Performansı: SWE-Bench ve Agent Yeteneklerinde Neden Zirvede?
Yapay zeka kodlama performansının ve otonom sistemlerin yeteneklerinin ölçüldüğü küresel kıyaslamalarda Claude Opus 4.5'un net bir liderlik sergilediğini görüyoruz: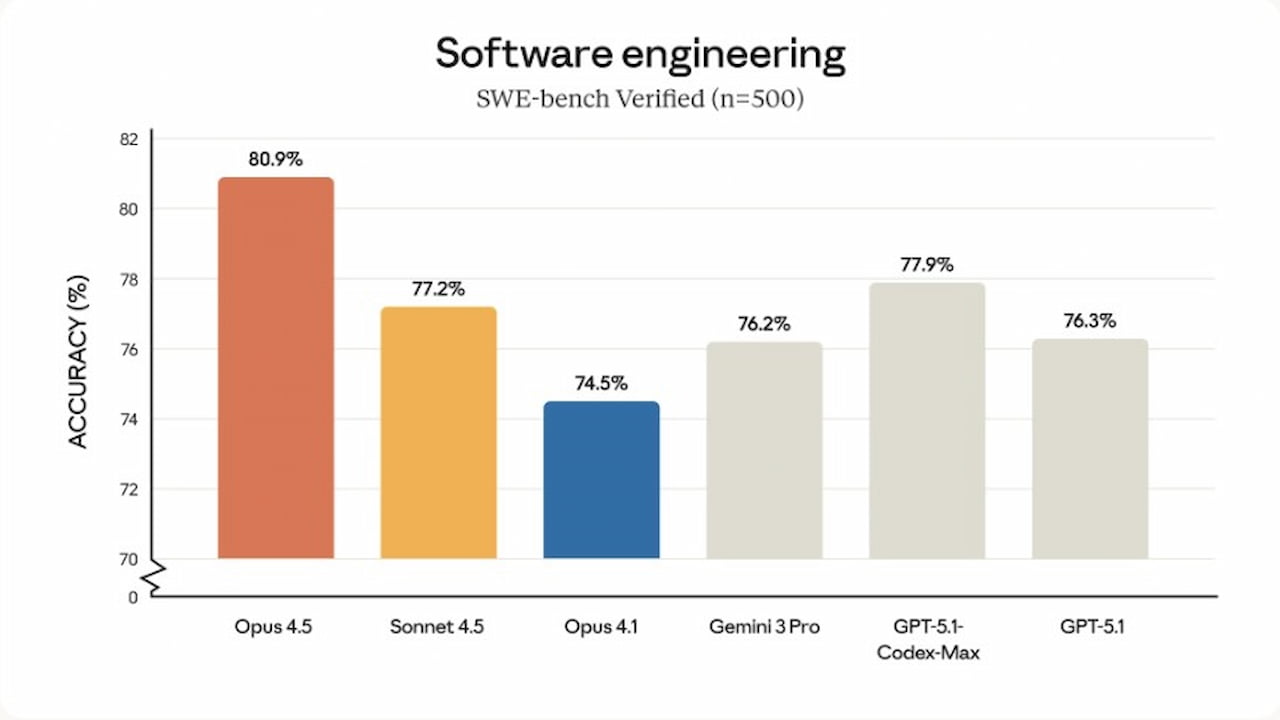
- SWE-bench Verified Liderliği: Gerçek GitHub sorunlarından oluşan ve bug onarım yeterliliğini ölçen SWE-bench Verified testinde, %80.9 civarında bir skorla %80 eşiğini geçen ilk model oldu. Bu, mühendislik bakım görevlerinin büyük çoğunluğunda makul düzeyde güçlü bir insan katkıcının performansını aştığı anlamına gelir.
- τ2-bench'te Yaratıcı Problem Çözme: τ2-bench gibi ajan yeteneklerini ölçen testlerde, modelin kısıtlamaların etrafından dolaşarak (örneğin, bileti değiştirmeden önce kabini yükselterek) politikalar dahilinde yasal ve yaratıcı çözümler üretmesi, sıradan otomasyonun ötesinde bir paralel akıl yürütme yeteneği sergilediğini gösteriyor. Bu zeka, onu AI ajan yeteneklerinde zirveye taşımasında büyük bir etken.
- İnsan Yeteneğini Geride Bırakma: Anthropic'in kendi zorlu mühendislik sınavında bile Opus 4.5'in en yüksek insan adaydan daha iyi skor alması, AI'ın teknik yargı ve beceri alanlarında geldiği seviyeyi gösteriyor.

Claude Opus 4.5 vs. GPT-5.1-Codex-Max Karşılaştırması
OpenAI'ın kodlama ve ajan odaklı uzman modeli GPT-5.1-Codex-Max ile Claude Opus 4.5 karşılaştırıldığında, iki modelin farklı stratejiler izlediği görülebilir:
| Özellik | Claude Opus 4.5 (Precision-Optimized Generalist) | GPT-5.1-Codex-Max (Endurance-Optimized Specialist) |
|---|---|---|
| Konumlandırma | Tüm alanlarda amiral gemisi, ancak kodlama ve bilimsel akıl yürütmede olağanüstü güçlü. | GPT-5.1 tabanında inşa edilmiş, uzun soluklu ajanik kodlama iş yüklerine odaklanmış uzman. |
| Bağlam Yönetimi | Büyük Statik Bağlam (200K+ token): Tüm orta ölçekli kod tabanını tek seferde görme yeteneği. | Bağlam Sıkıştırma (Compaction): Tarihçeyi özetleyerek durumu korur ve milyonlarca token üzerinde tutarlı kalabilir. |
| SWE-Bench Doğruluğu | Hafif Liderlik (≈%80.9): Hata düzeltme (bug-fixing) metriklerinde istatistiksel olarak daha iyi. | Yüksek Performans (≈%77.9): Yüksek akıl yürütme modunda bile Opus'un biraz gerisinde. |
| Ekonomi ve Verimlilik | Token Verimliliği: Sonnet 4.5'ten %76 daha az çıktı token'ı kullanabilir. Ancak Opus 4.5 fiyatlandırması (girdi/çıktı: 5$/25$ per 1M token) Codex-Max'e göre daha yüksektir. | Maliyet Avantajı: Daha düşük token fiyatları (Opus'a göre yaklaşık 2.5-4 kat daha ucuz), uzun süreli aracı döngüleri için ekonomiktir. |
| Geliştirici Kontrolü | Effort Parameter: Kullanıcının, hız/maliyet (düşük efor) veya maksimum doğruluk (yüksek efor) arasında seçim yapmasını sağlar. | xhigh Modu: En yüksek akıl yürütme için derin dahili düşünme bütçesi sunar. |
| Uygulama Alanı | Bilimsel orkestrasyon (CORE-Bench'te güçlü), mimari tasarım, risk analizi, web tarayıcı kontrolü. | CLI merkezli, uzun soluklu hata ayıklama, büyük refaktörler ve terminal içi entegrasyonlar. |
Anthropic'in Geliştirici Platformu ve Ekonomi Stratejisi
Anthropic, Claude Agent SDK ve geliştirici platformundaki yeniliklerle ekosistemini güçlendirdi:
- Claude Agent SDK: Modelin ham zekasını pratik, gerçek dünya görevlerine dönüştüren bir "harness" (koşum takımı) sunar. Bu SDK, ajanların uzun zaman ufuklarında güvenilir bir şekilde çalışmasını sağlayan kritik bir bileşendir. Mckay Wrigley, bu ikiliyi "ajanlar için bir Waymo anı" olarak nitelendirerek, AI'ın artık otonom olarak iş yaptığını vurguluyor.
- Effort Parameter ve Token Ekonomisi: Yeni “effort parameter”, geliştiricilere modelin kaynak kullanımını kontrol etme yetkisi verir. En yüksek efor seviyesinde Opus 4.5, daha az eforlu Sonnet 4.5'i %4.3 puanla geçerken, %48 daha az token tüketir. Bu token verimliliği, Opus 4.5 fiyatlandırmasının daha yüksek olmasına rağmen, uzun vadede maliyet etkinliği sağlar.
- Context Compaction: Claude uygulamasında, uzun sohbetlerin bağlam kaybı yaşamasını önlemek için otomatik özetleme (context compaction) mekanizması devreye alınmıştır. Bu, ajanın uzun süreli görevlerde "konuyu unutmasını" engeller.
- Ürün Entegrasyonları: Claude Code uygulaması masaüstünde birden fazla yerel ve uzak oturumu paralel olarak çalıştırabilir. Ayrıca Claude for Excel ve Claude for Chrome gibi entegrasyonlar, modelin tarayıcılar ve elektronik tablolar üzerinde kontrol sağlayarak "bilgisayar kullanma" yeteneğini artırıyor.
Güvenlik ve Risk Yönetimi: Prompt Injection ve Reward Hacking
Anthropic, Claude Opus 4.5'i prompt injection dayanıklılığı açısından endüstri lideri konumuna yerleşmiş durumda.
Prompt Injection Dayanıklılığı
Model, kötü niyetli saldırganların aldatıcı talimatlarını gizlemesini zorlaştırmak için sistematik olarak güçlendirilmiştir. Bu, özellikle hassas kod tabanları ve kurumsal verilerle çalışan ajanlar için hayati bir güvenlik katmanıdır.

Reward Hacking ve Hizalanma (Alignment)
Modelin, havayolu örneğinde olduğu gibi, kuralların etrafından dolaşarak yaratıcı çözümler bulması, istenmeyen veya etik dışı yollarla hedefe ulaşma riski olan reward hacking potansiyelini de beraberinde getirir. Anthropic, bu tür istenmeyen hizalanma (misalignment) risklerini önlemek için güvenlik testlerine devam ettiğini ve Opus 4.5'in bugüne kadar çıkardıkları en sağlam hizalanmış model olduğunu iddia ediyor.
Claude Opus 4.5, yazılım mühendisliği, bilimsel akıl yürütme ve otonom ajan geliştirme alanlarında net bir ilerleme kaydetmiştir. Bu model, Anthropic'in sadece yüksek zekalı bir LLM değil, aynı zamanda güvenilir ve kontrol edilebilir bir AI İş Akışı Otomasyonu platformu sunma hedefini pekiştiriyor.
