
DeepSeek V4 Tanıtıldı: 1 Milyon Token ve 1.6T Parametre!
Çin merkezli DeepSeek, V4 modeliyle 1 milyon token bağlam ve 1.6 trilyon parametreye ulaşarak yapay zekada ölçek, verimlilik ve maliyet dengesini yeniden tanımlıyor.

DeepSeek V4 Nedir ve Neden Önemli?
Yapay zeka alanında rekabet yalnızca model doğruluğu üzerinden değil; bağlam uzunluğu, işlem maliyeti ve ölçeklenebilirlik gibi parametreler üzerinden yeniden tanımlanırken, DeepSeek tarafından tanıtılan DeepSeek V4 modeli bu dönüşümün en somut örneklerinden biri olarak konumlanıyor. “DeepSeek V4 nedir?” sorusu, yalnızca yeni bir model tanımıyla sınırlı değil; aynı zamanda büyük dil modellerinin (LLM) teknik mimarisinde yaşanan kırılmayı ifade ediyor. Modelin 1 milyon token bağlam kapasitesi, uzun metin işleme, kod analizi ve çok aşamalı akıl yürütme görevlerinde radikal bir genişleme sunarken, 1.6 trilyon parametre ölçeği, yapay zekanın hesaplama gücünde ulaştığı yeni eşiği temsil ediyor.
Bu gelişme, özellikle veri yoğun sektörlerde finans, hukuk, yazılım mühendisliği ve akademik araştırmalarda tek oturumda daha fazla bilgi işlenebilmesini mümkün kılıyor. Geleneksel modellerde bağlam sınırına takılan analiz süreçleri, artık çok daha geniş veri kümeleri üzerinde kesintisiz şekilde yürütülebiliyor. Bu durum, yalnızca performans artışı değil, aynı zamanda iş akışlarının yeniden tasarlanması anlamına geliyor.
DeepSeek V4 serisi, yalnızca ölçek büyümesi değil aynı zamanda mimari yeniden tasarım anlamına geliyor. DeepSeek tarafından geliştirilen model ailesi; DeepSeek-V4-Pro ve DeepSeek-V4-Flash olmak üzere iki farklı yapı ile sunuluyor. Resmi Hugging Face koleksiyonunda açık kaynak olarak yayımlanan model, 1M context standardını sektörde yeni bir norm haline getirmeyi hedefliyor.
1 Milyon Token Yapay Zeka: Bağlam Sınırları Kalkıyor
DeepSeek V4’ün en dikkat çekici yeniliklerinden biri olan 1 milyon token bağlam kapasitesi, yapay zeka modellerinde bugüne kadar karşılaşılan en büyük teknik sıçramalardan biri olarak değerlendiriliyor. Token, bir metnin işlenebilir en küçük birimlerinden biri olarak tanımlanırken, bu kapasitenin 1 milyona ulaşması; yüzlerce sayfalık dokümanların, büyük kod tabanlarının veya çok katmanlı veri setlerinin tek seferde analiz edilebilmesi anlamına geliyor.
Bu gelişme, özellikle uzun bağlam gerektiren görevlerde ciddi bir avantaj yaratıyor. Örneğin; bir hukuk metninin tamamının analiz edilmesi, büyük ölçekli yazılım projelerinde hata ayıklama veya akademik makalelerin kapsamlı karşılaştırmalı incelemesi gibi işlemler, artık parça parça değil bütüncül şekilde gerçekleştirilebiliyor. Bu da modelin “hafıza sürekliliği” sorununu büyük ölçüde ortadan kaldırıyor.
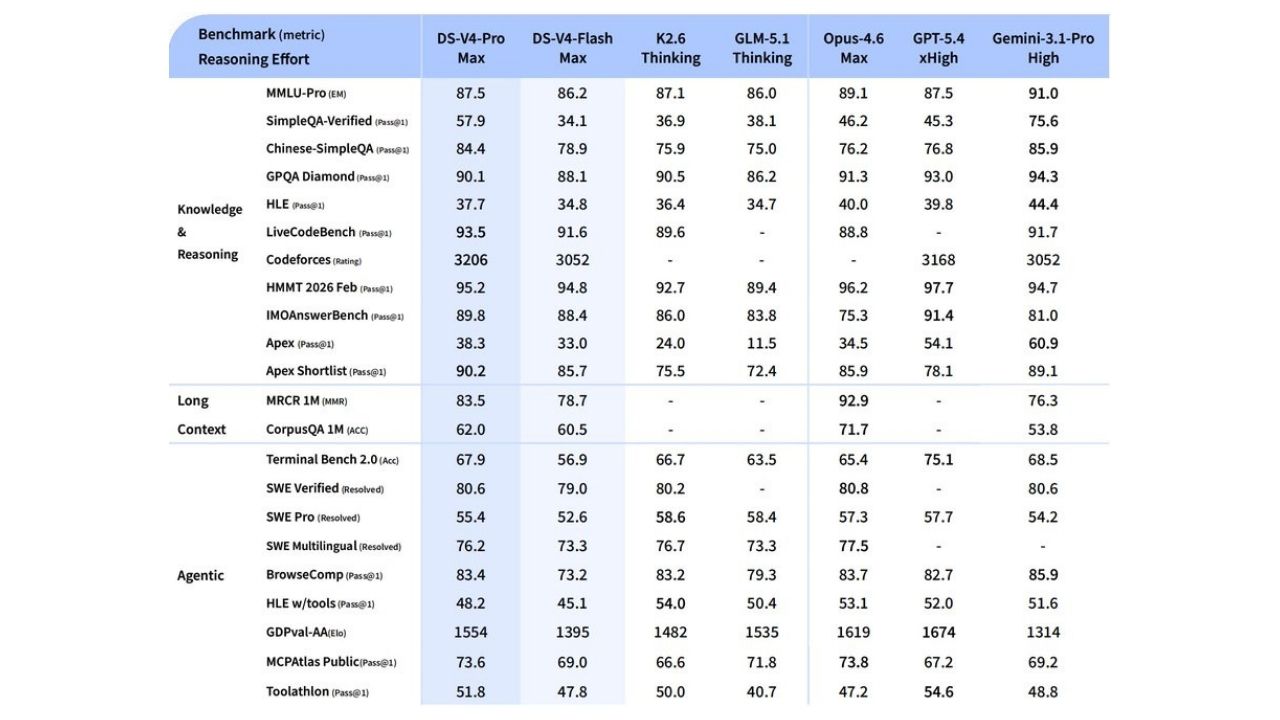
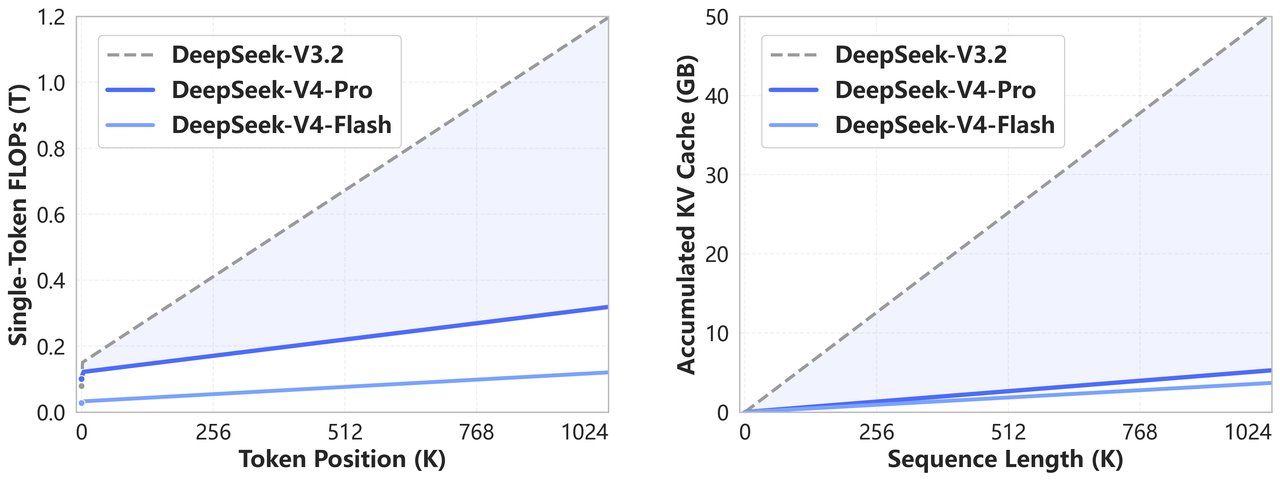
DeepSeek V4, Hybrid Attention mimarisi sayesinde uzun bağlam işlemede ciddi verimlilik kazanımları sunuyor. Compressed Sparse Attention (CSA) ve Heavily Compressed Attention (HCA) kombinasyonu ile model, önceki nesillere göre çok daha düşük hesaplama maliyetiyle çalışabiliyor. Özellikle 1M token senaryosunda KV cache kullanımının ciddi oranda düşürüldüğü belirtiliyor.
Mixture of Experts Mimarisi: Ölçeklenebilir Zeka Yaklaşımı
DeepSeek V4’ün teknik omurgasında yer alan Mixture of Experts (MoE) mimarisi, modelin yüksek parametre sayısına rağmen verimli çalışmasını sağlayan temel mekanizma olarak öne çıkmaktadır. Bu mimari, tüm modelin aynı anda çalıştırılması yerine, belirli görevler için yalnızca ilgili “uzman” alt ağların aktive edilmesini sağlıyor.
Bu yaklaşım, klasik yoğun (dense) modellere kıyasla ciddi bir hesaplama avantajı sunuyor. 1.6 trilyon parametreye sahip bir modelin tamamını her işlemde kullanmak yerine, yalnızca gerekli parçaların devreye alınması; hem işlem maliyetini düşürüyor hem de yanıt süresini optimize ediyor. Bu durum, özellikle API kullanımında maliyet-performans dengesini doğrudan etkileyen kritik bir faktör olarak öne çıkmakta.
Ayrıca MoE mimarisi, modelin farklı görev türlerinde uzmanlaşabilmesini mümkün kılarak daha yüksek doğruluk oranları sağlıyor. Bu da DeepSeek V4’ü yalnızca büyük değil, aynı zamanda “akıllı ölçeklenen” bir model haline getiriyor.
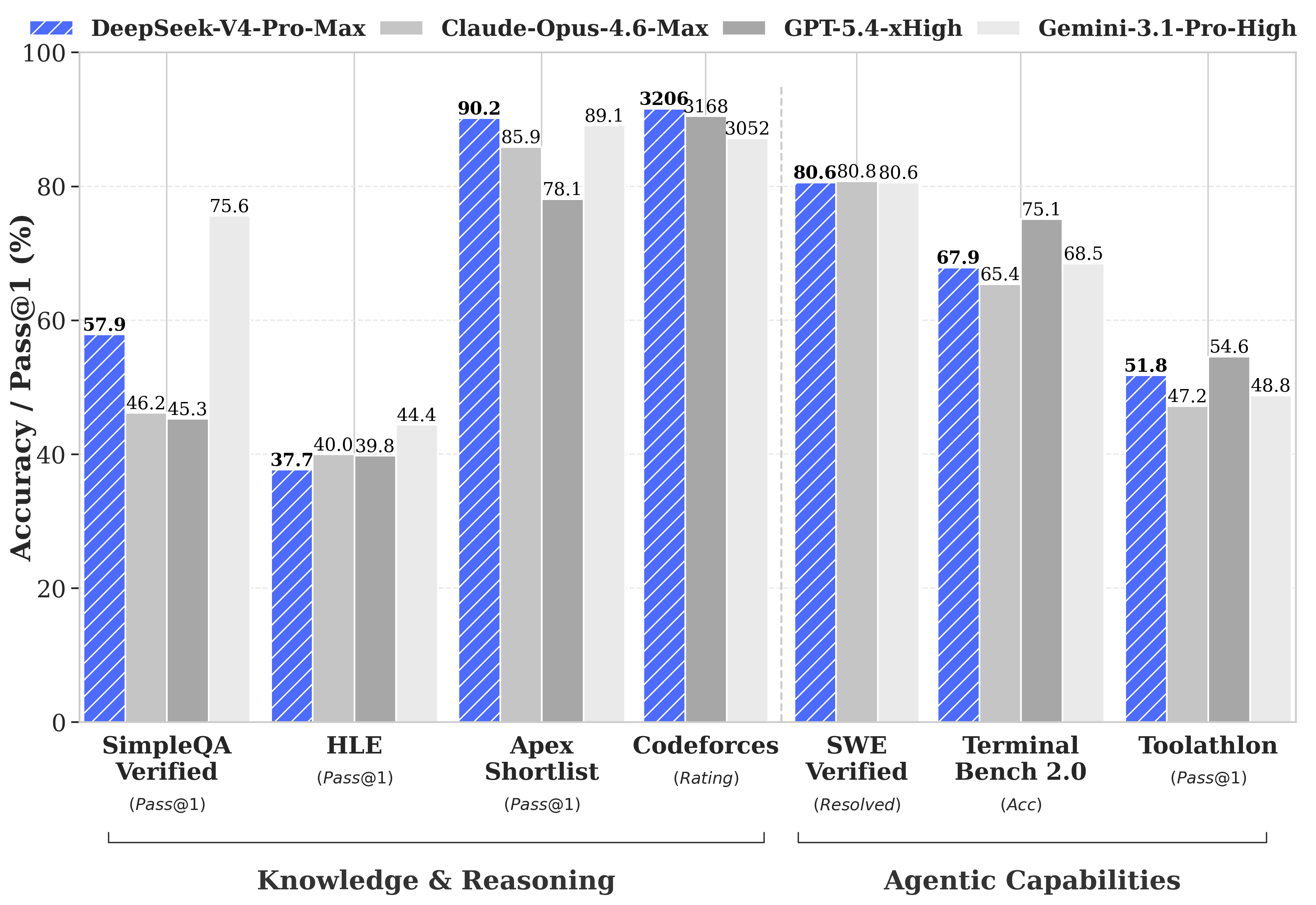
DeepSeek V4 mimarisi içerisinde Pro ve Flash modelleri farklı aktif parametre seviyeleriyle ayrışıyor. DeepSeek-V4-Pro 1.6T toplam parametre içinde 49B aktif parametre kullanırken, DeepSeek-V4-Flash 284B toplam parametre içinde 13B aktif parametre ile çalışıyor. Bu yapı, MoE mimarisinin temel avantajı olan “gerektiği kadar hesaplama” prensibini doğrudan uyguluyor.
DeepSeek V4’ün mimarisinde yer alan Manifold-Constrained Hyper-Connections (mHC) yapısı, katmanlar arası bilgi akışını stabilize ederken modelin ifade gücünü korumasını sağlıyor. Ayrıca Muon optimizer kullanımı, eğitim sürecinde daha hızlı convergence ve daha stabil learning dynamics sunuyor.
KV Cache Verimliliği: Uzun Bağlamın Gizli Gücü
Uzun bağlam kapasitesinin pratikte verimli kullanılabilmesi için kritik olan bir diğer unsur ise KV Cache (Key-Value Cache) optimizasyonu olarak öne çıkıyor. DeepSeek V4’te geliştirilen KV Cache verimliliği, modelin önceki token’ları yeniden hesaplamadan kullanabilmesini sağlayarak işlem yükünü önemli ölçüde azaltıyor.
Bu teknik iyileştirme, özellikle uzun diyaloglar ve sürekli veri akışı gerektiren uygulamalarda performansı doğrudan etkiliyor. Örneğin; bir kullanıcıyla uzun süreli etkileşimde bulunan bir yapay zeka sistemi, her yeni girişte tüm geçmişi yeniden işlemek zorunda kalmadan hızlı ve tutarlı yanıtlar üretebiliyor.
KV Cache optimizasyonu aynı zamanda enerji verimliliği açısından da kritik bir rol oynuyor. Daha az hesaplama gereksinimi, daha düşük enerji tüketimi anlamına gelirken; bu durum büyük ölçekli veri merkezlerinde operasyonel maliyetleri doğrudan etkiliyor.
DeepSeek V4-Pro, DeepSeek-V3.2’ye kıyasla 1M context senaryosunda yaklaşık %10 KV cache kullanımı ile çalışırken, inference FLOPs tarafında da %27 seviyesinde daha verimli bir yapı sunuyor. Bu optimizasyon özellikle uzun sohbet ve agent tabanlı uygulamalarda önemli performans artışı sağlıyor.
DeepSeek V4 Pro Özellikleri: Kurumsal Seviyede Performans
DeepSeek V4 Pro, model ailesinin en güçlü versiyonu olarak konumlandırılıyor ve özellikle kurumsal kullanım senaryolarına odaklanıyor. Gelişmiş akıl yürütme yetenekleri, uzun bağlam yönetimi ve yüksek doğruluk oranları, bu versiyonu büyük veri işleme gerektiren projeler için ideal hale getiriyor.
Pro versiyonun en önemli özelliklerinden biri, karmaşık görevlerde daha tutarlı sonuçlar üretebilmesi. Çok adımlı problem çözme, ileri seviye kod üretimi ve analitik görevlerde, modelin performansı belirgin şekilde öne çıkıyor. Ayrıca, API üzerinden sunulan esnek yapı sayesinde şirketler kendi ihtiyaçlarına göre modeli entegre edebiliyor.
DeepSeek V4 Flash vs Pro: Performans ve Maliyet Dengesi
DeepSeek V4 ailesinde yer alan Flash ve Pro versiyonları, farklı kullanım senaryolarına hitap edecek şekilde konumlandırılmış durumda. Flash versiyon, daha düşük gecikme süresi ve maliyet avantajı sunarken; Pro versiyon, maksimum performans ve doğruluk odaklı çalışıyor.
Flash modeli, gerçek zamanlı uygulamalar chatbotlar, müşteri hizmetleri ve hızlı içerik üretimi gibileri için optimize edilmiş durumda. Buna karşılık Pro modeli, daha ağır ve karmaşık görevlerde tercih ediliyor. Bu ayrım, geliştiricilerin ihtiyaçlarına göre doğru modeli seçebilmesini sağlıyor.
Flash modeli, Pro versiyona kıyasla daha küçük aktif parametre yapısı sayesinde daha düşük gecikme süresi sunarken, basit agent görevlerinde Pro seviyesine yakın performans gösterebiliyor. Buna karşın Pro model, özellikle karmaşık reasoning, coding ve bilimsel problem çözme görevlerinde açık ara daha güçlü sonuçlar üretiyor.
DeepSeek V4 API Fiyatlandırması: Rekabetçi Strateji
DeepSeek V4 API fiyatlandırması, modelin teknik kapasitesi göz önüne alındığında agresif bir rekabet stratejisi olarak değerlendiriliyor. Özellikle MoE mimarisi sayesinde düşürülen işlem maliyetleri, kullanıcıya daha uygun fiyatlı bir API deneyimi olarak yansıyor.
Bu durum, pazarda OpenAI ve Google gibi büyük oyuncularla rekabeti doğrudan etkileyen bir faktör olarak öne çıkıyor. Daha uzun bağlam, daha düşük maliyet ve yüksek performans kombinasyonu, DeepSeek’in küresel yapay zeka yarışında güçlü bir konum elde etmesini sağlıyor.
DeepSeek V4 API, OpenAI ChatCompletions ve Anthropic uyumlu yapı ile çalışıyor. Kullanıcılar yalnızca model adını deepseek-v4-pro veya deepseek-v4-flash olarak değiştirerek mevcut sistemlerine entegre edebiliyor. Ayrıca “thinking mode” ve “non-thinking mode” gibi farklı reasoning seviyeleri destekleniyor.
Küresel Yapay Zeka Yarışında Yeni Denge
DeepSeek V4’ün tanıtımı, yalnızca teknik bir gelişme değil; aynı zamanda küresel yapay zeka rekabetinde yeni bir denge noktası oluşturuyor. Çin merkezli şirketlerin bu alandaki hızlı ilerleyişi, ABD merkezli teknoloji devleriyle olan rekabeti daha da kızıştırıyor.
Bu bağlamda, NVIDIA altyapıları üzerinde geliştirilen modellerin performansı da dikkat çekiyor. Donanım ve yazılım entegrasyonunun optimize edilmesi, yapay zekanın geleceğinde belirleyici rol oynayan unsurlar arasında yer alıyor.
Ölçek, Verimlilik ve Gelecek Perspektifi
DeepSeek V4, yapay zekada yalnızca daha büyük modellerin değil; daha verimli, daha ölçeklenebilir ve daha erişilebilir sistemlerin önem kazandığı yeni bir dönemin habercisi olarak değerlendiriliyor. 1 milyon token bağlam kapasitesi, 1.6 trilyon parametre ve gelişmiş mimari optimizasyonlar; bu modelin yalnızca bugünü değil, önümüzdeki yılların yapay zeka standartlarını da şekillendireceğini gösteriyor.
Bu gelişme, yapay zekanın yalnızca teknoloji şirketleri için değil; tüm sektörler için stratejik bir altyapı haline geldiğini bir kez daha ortaya koyuyor. DeepSeek V4 ile birlikte, “daha büyük model” anlayışı yerini “daha akıllı ve verimli model” paradigmasına bırakıyor.
DeepSeek V4, küresel yapay zeka yarışında özellikle açık kaynak tarafında önemli bir kırılma noktası yaratıyor. Modelin açık ağırlıklarla yayımlanması, kapalı sistemlere alternatif bir ekosistem oluşturma potansiyelini güçlendiriyor.
Yorumlar (0)
Yorum yapmak için giriş yapmalısınız.
Giriş Yap