
Gemini Kullanım Limiti Sistemi Tamamen Değişiyor
Google, yapay zeka dünyasında uzun süredir alışık olduğumuz tüketim alışkanlıklarını kökten değiştirecek bir hamlenin eşiğinde. Bugüne kadar ChatGPT, Claude veya Gemini fark etmeksizin"3 saatte 40 mesaj" ya da "günlük X adet sorgu" şeklindeki kotaların devri kapandı. Google, Gemini arayüzünde sessiz sedasız ama geliştiricileri doğrudan etkileyecek "compute based AI", yani işlem gücü temelli bir kota sistemine geçiş yapıyor. İlk bakışta arayüzdeki küçük bir metin güncellemesi gibi duran bu hamle, aslında arka planda devasa bir mimari ve iş modeli değişimine işaret ediyor. Artık attığımız her prompt, havuzdan eşit miktarda hak eksiltmeyecek. Beş satırlık basit bir fonksiyonun hatasını bulmakla, yüz binlerce token’lık bütünsel bir repository analizi yaptırmak aynı potada erimeyecek. Özellikle üretim süreçlerinde Gemini’ı ana partneri haline getiren yazılımcılar için bu değişim, workflow tasarımlarını baştan aşağı optimize etmeyi zorunlu kılıyor.

Chatbot Deneyiminden Bulut Bilişim Mantığına: Gemini’da Neler Değişiyor?
Yapay zeka araçları ilk yaygınlaştığında sistem basit bir soru-cevap mekanizmasından ibaretti. Kullanıcı bir girdi veriyor, model doğrudan bir çıktı üretiyordu. Bu doğrusal akış, bulut sağlayıcılarının geleneksel sunucu isteklerini fiyatlandırmasına benziyordu. Ancak günümüzde LLM'ler artık sadece kelime tahminleyen algoritmalar değil. Model arkada düşünüyor, plan yapıyor, kendi ürettiği kodu test ediyor ve adım adım mantık yürütüyor.
Google’ın üzerinde çalıştığı yeni sistem, tam olarak bu noktada geleneksel chatbot mantığını öldürüp yerine AWS, Google Cloud veya Azure’dan aşina olduğumuz saf işlem gücü odaklı fiyatlandırma/kota mimarisini getiriyor. Bir sunucuda ne kadar CPU, GPU ve RAM tüketirseniz o kadar fatura ödediğiniz bulut bilişim mantığı, artık Gemini arayüzündeki prompt’larımıza uygulanıyor. Tükettiğimiz şey artık "mesaj sayısı" değil, Google veri merkezlerindeki çiplerin harcadığı saniyeler ve işlem döngüleri.
Android Police Sızıntısı Ne Diyor? Günlük Sorgu Mantığının Sonu
Bu köklü değişimin ilk somut ayak sesleri, Android Police ekibinin Gemini arayüz kodlarında ve arka plan güncellemelerinde yakaladığı detaylarla ortaya çıktı. Sızıntılara göre Google, kullanıcı arayüzünde yer alan ve kalan hakları sembolize eden "remaining requests" (kalan istekler) mantığını aşamalı olarak tedavülden kaldırıyor. Bunun yerine sistem, kullanıcının yaptığı işlemlerin ağırlığına göre dinamik olarak güncellenen, arka planda karmaşık bir compute metriğine dayanan yeni bir takip mekanizması getiriyor.
Geliştirici Workflow'larında "Remaining Requests" Döneminin Kapanışı
Yazılım geliştirirken editör entegrasyonları veya web arayüzü üzerinden sürekli Gemini ile konuşanlar iyi bilir; gün içinde kaç hakkınızın kaldığını bilmek iş planlaması yapmak açısından hayati önem taşır. Eski sistemde, kritik bir refactor işlemine girişmeden önce "Daha 20 mesaj hakkım var, rahatça bitiririm" diyebiliyordunuz. Ancak Android Police'in ortaya çıkardığı yeni yapıda bu tahminlenebilirlik ortadan kalkıyor. Tek bir ağır prompt, arka plandaki tüm işlem havuzunuzu kurutabilir. Bu durum, özellikle yoğun çalışan bağımsız geliştiriciler ve ajanslar için günlük kaynak yönetimini zorlaştırıyor.
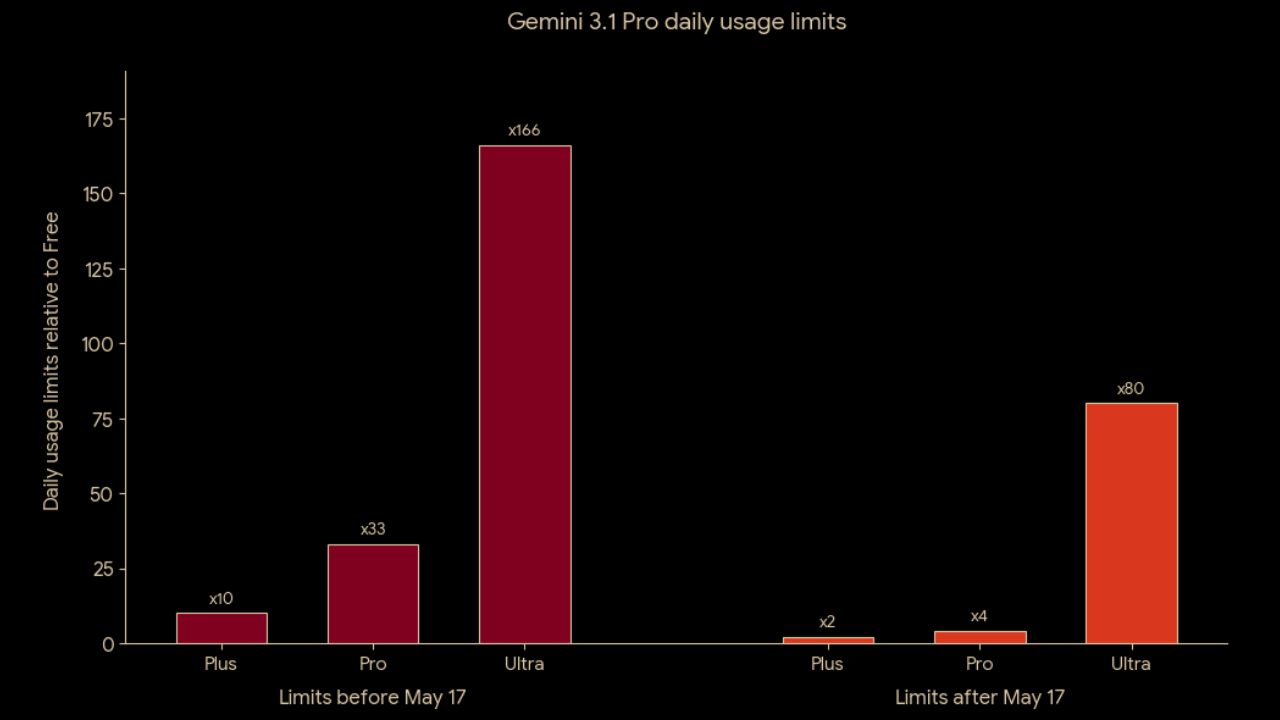
Compute Based AI Tam Olarak Ne Demek? Her Prompt Neden Eşit Değil?
Pazarlama departmanlarının süslü bir kelimesi gibi duran "Compute based AI", teknik tarafta tamamen donanımsal gerçekliklere dayanıyor. Bu sistemde attığınız bir prompt’un maliyeti ve kotanızdan götüreceği miktar sabit kalmıyor. Kullanımınızın arkasında çalışan GPU'ların ne kadar terlediği hesaplanıyor.
Compute Tüketimini Doğrudan Etkileyen Üç Temel Değişken
Prompt Karmaşıklığı: Basit bir "CSS'te elementi nasıl ortalarım?" sorusu ile "Şu mikroservis mimarisindeki deadlock problemini analiz et" komutu aynı kefede tartılmıyor. İkinci komut, modelin çok katmanlı düşünme ağlarını tetikliyor ve daha fazla inference gücü harcıyor.
Context Uzunluğu: Gemini’ın en büyük kası olan devasa context window, en büyük maliyet kalemi haline gelmiş durumda. Modeli beslediğiniz her log dosyası, dokümantasyon sayfası veya kod bloku, dikkat mekanizmasının quadratik olarak daha fazla compute harcamasına neden oluyor.
Thinking Mode ve Akıl Yürütme Süresi: Modelin yanıt vermeden önce "düşünme" aşamasına geçmesi, arka planda yüzlerce görünmez token üretilmesi ve kendi kendini düzeltme döngülerine girmesi anlamına geliyor. Kullanıcı sadece tek bir çıktı görüyor ama arka planda harcanan elektrik ve işlemci gücü katlanıyor.
Gemini 2.5 Pro ve Reasoning Modellerinin Getirdiği Maliyet Yükü
Google’ın özellikle Gemini 2.5 Pro döneminde bu kararı vermesi şaşırtıcı değil. Sektör genelinde OpenAI’ın o-serisi modelleri, Anthropic tarafındaki Claude Sonnet reasoning güncellemeleri derken yapay zekanın yönü tamamen "akıl yürütme" bacağına kaydı. Ancak bu durum teknoloji devleri için korkunç bir donanım ve enerji maliyetini beraberinde getirdi.

Gemini 2.5 Pro gibi 1 milyondan fazla token context penceresine sahip, derin araştırma yapabilen ve karmaşık kod bloklarını analiz eden bir modeli eski usul "günde sabit 50 mesaj" mantığıyla sunmak ekonomik bir intihardı. Çünkü bir kullanıcı bu 50 hakkı sadece sohbet ederek tüketirken, bir geliştirici tüm repository'sini modele yükleyip 50 kez devasa analizler yaptırabiliyordu. Aradaki maliyet farkı binlerce katı bulabildiği için Google, adil kullanım kotasını tabana yaymak adına compute temelli modele geçmek zorunda kaldı.
Google AI Pro Abonelerini ve Geliştiricileri Ne Bekliyor?
Aylık ücret ödeyerek Google AI Pro abonesi olan kullanıcıları önümüzdeki dönemde biraz sisli bir süreç bekliyor. Google şu aşamada net sınırları, sayısal limitleri veya compute birimlerini şeffaf bir şekilde panellere yansıtmış değil. Ancak test süreçlerinden ve forum sızıntılarından anlaşıldığı kadarıyla kullanıcı deneyiminde şu senaryolar netleşmeye başladı:
Yoğun kod analizi yapan ve büyük projeleri mimari seviyede Gemini'a inceleten ekipler, günlük limitlerine çok daha erken toslayacaklar. Buna karşılık, gün içinde sadece mailleri düzenleyen, basit script'ler yazan veya metin özetleten casual kullanıcılar belki de günlerce hiç limite takılmadan sistemi kullanabilecek. Model, ağır iş yapanlardan hakkını hızlıca tahsil ederken, hafif iş yapanları sistemde daha uzun süre tutacak.
Prompt Engineering Yaklaşımımız Nasıl Değişecek? Token ve Compute Optimizasyonu
"Nasılsa sınırsız" ya da "Nasılsa günlük 100 hakkım var" rahatlığıyla baştan savma yazılan uzun prompt dönemi resmi olarak kapanıyor. Bu yeni dönem, yazılımcıların prompt engineering yaklaşımını doğrudan etkileyecek. Eskiden API tarafında yaptığımız "token optimization" ve maliyet düşürme taktikleri, artık tarayıcıdaki Gemini App arayüzüne de taşınacak.
Geliştiricilerin yeni dönemde Gemini quota sınırları içinde hayatta kalabilmesi için şu pratikleri alışkanlık haline getirmesi gerekiyor:
Modüler Prompting: Tüm projeyi tek seferde modele fırlatmak yerine, sadece üzerinde çalışılan ilgili modülleri veya fonksiyon bloklarını beslemek.
Context Temizliği: Chat geçmişinde kalan ve artık mevcut task ile ilgisi olmayan eski kod çıktılarını temizleyerek modelin her seferinde o devasa geçmişi yeniden okumasını engellemek.
Doğru Göreve Doğru Model: Basit regex yazımı, basit hata yakalamaları için thinking mode'u kapatmak veya daha hafif modelleri tercih etmek; derin mimari tasarımları ise saklayıp sadece gerektiğinde pro reasoning modunda çalıştırmak.

Reddit ve Geliştirici Forumlarındaki "Sessiz Kota" Tartışmaları
Resmi duyurular tam olarak netleşmeden önce bile topluluk bu değişimi hissetmeye başlamıştı. Özellikle Reddit'in r/LocalLLM, r/Bard ve çeşitli yazılımcı subbreddit'lerinde son birkaç aydır "Aynı sayıda prompt atmama rağmen bugün limitim neden 2 saatte bitti?" başlıkları açılıyordu.
Geliştiriciler, özellikle büyük kod tabanları üzerinde çalışırken sistemin kendilerini çok daha agresif bir şekilde engellediğini fark ettiler. Bu durum, Google’ın compute tabanlı AI modelini aslında prodüksiyona almadan önce canlı ortamda sessizce test ettiğinin en büyük kanıtı oldu. Topluluğun buradaki en büyük eleştirisi ise şeffaflık eksikliği. Yazılımcılar haklı olarak panellerinde kaç "Compute Unit" harcadıklarını, hangi prompt’un havuzu ne kadar tükettiğini şeffaf bir şekilde görmek istiyor.
Gemini API ve Gemini App Limiti Arasındaki Çizgi Eriyor mu?
Burada kafa karışıklığını gidermek adına önemli bir ayrım yapmak gerekiyor. Gemini API kullanan geliştiriciler için bu mantık aslında yepyeni bir şey değil. API dünyasında zaten yıllardır TPM, RPM ve token bazlı ücretlendirme modelleri geçerli. Yazılımcılar yazdıkları kodun maliyetini harcanan token üzerinden zaten kuruşu kuruşuna hesaplıyordu.
Değişen şey, API ekonomisinin ve oradaki acımasız kaynak optimizasyon mantığının artık doğrudan son kullanıcı arayüzü olan Gemini App tarafına taşınması. Google, chatbot kullanan standart son kullanıcıyı ve arayüz üzerinden çalışan yazılımcıyı da API benzeri bir hardeme matrisine tabi tutarak kaynak sömürüsünün önüne geçmeyi hedefliyor.
Yapay Zeka Yarışında Yeni Perde: Inference Economics ve Maliyet Yönetimi
Günün sonunda olay sadece Google’ın kotayı nasıl hesapladığı değil. Yapay zeka dünyasında artık yeni bir faza geçtik: Inference Economics. Sektördeki hiçbir dev, milyarlarca dolarlık GPU yatırımlarını son kullanıcılara "sınırsız ve kontrolsüz" bir şekilde sunamaz. Model kaliteleri birbirine yaklaştıkça, asıl kazanan bu modelleri en optimize maliyetle halka sunabilen şirket olacak.
Google'ın attığı bu compute based AI adımı, yapay zeka pazarının olgunlaştığının ve sürdürülebilirlik evresine geçtiğinin bir göstergesi. Önümüzdeki dönemde muhtemelen rakiplerinden de benzer hamleler göreceğiz. Geliştiriciler olarak yapmamız gereken ise bu yeni düzene ayak uydurmak, promptlarımızı daha zekice tasarlamak ve kod yazarken yapay zekayı bir "token canavarı" gibi değil, hassas bir bulut kaynağı gibi yönetmeyi öğrenmek.
Sıkça Sorulan Sorular
Gemini kullanım limiti nedir?
Google’ın yapay zeka modellerini suistimalden korumak ve sunucu yükünü dengelemek adına kullanıcı başına tanımladığı maksimum işlem sınırıdır. Yeni sistemle birlikte bu sınır artık adet bazlı değil, işlem gücü bazlı hesaplanmaktadır.
Google AI Pro limiti ne kadar?
Google AI Pro aboneliğinde sabit bir mesaj sayısı belirtilmemektedir. Limitler esnektir ve o anki sunucu yoğunluğuna, kullandığınız modelin tipine ve prompt’larınızın harcadığı compute miktarına göre dinamik olarak değişir.
Gemini quota ne anlama geliyor?
Kullanıcının belirli bir zaman dilimi içinde yapay zeka modeline yaptırabileceği toplam iş hacmini ifade eder. Yeni sistemde quota, harcanan token derinliği ve modelin akıl yürütme süresiyle doğrudan ilişkilidir.
Gemini kullanım limiti ne zaman sıfırlanıyor?
Genellikle sabit bir takvim günü yerine "rolling window" mantığı kullanılır. Yoğun kullanım sonrası dolan limitler, sistemin yoğunluğuna göre genellikle birkaç saatlik periyotlarla kademeli olarak sıfırlanır.
Compute based AI sistemi ücretleri artırır mı?
Mevcut abonelik ücretlerinde doğrudan bir artış anlamına gelmeyebilir ancak yoğun kullanan profesyoneller ve yazılımcılar için gelecekte daha yüksek compute paketleri içeren üst segment abonelik modellerinin çıkmasına zemin hazırlayabilir.
Gemini API ve Gemini App limitleri aynı mı?
Hayır, tamamen farklıdır. Gemini API kullandığınız kadar ödediğiniz ya da projeye özel tanımlanan kesin token limitleriyle çalışırken; Gemini App kullanıcı arayüzü abonelik modeline dayalı esnek ve dinamik bir compute kotası kullanır.
Yorumlar (0)
Yorum yapmak için giriş yapmalısınız.
Giriş Yap