
Veri Altyapısı Tahminleri: 2026'da Sizi Neler Bekliyor?
Veri altyapısı, 2026’da veri depolama ve raporlama ihtiyacını karşılayan arka plan sistemleri olmaktan çıktı. Bu şekilde yapay zeka; otonom karar mekanizmaları ve gerçek zamanlı analitik süreçlerin temel belirleyicisi haline gelmiş oldu. Bugün hangi veriye sahip olunduğundan çok, verinin nasıl modellendiği ve nasıl anlamlandırıldığı ile de doğrudan ilgili duruma geldi. Bu dönüşüm; geleneksel veri ambarlarını, katı ETL boru hatlarını ve analitik–operasyonel ayrımını doğrudan sorgulamaktadır. 2026 tahminlerine göre; veri altyapısında daha açık, daha modüler ve AI uyumlu mimariler öne çıkacak.

Analitik ve Operasyonel Sistemlerin Sonu mu Geliyor?
Klasik veri mimarisi anlayışı, yıllar boyunca iki ayrı dünya üzerine inşa edildi. Bunlar günlük işlemleri yürüten Operasyonel Sistemler (OLTP) ile raporlama ve karar destek sağlayan Analitik Sistemler (OLAP) olarak sıralanabilir. Bu yaklaşım, veri çoğaltmada yaşan gecikmeleri ve karmaşık entegrasyon katmanlarını kaçınılmaz kılıyordu. Ancak modern dijital ürünler ile bu ayrımın sonuna yaklaşıldı.
Bu Ayrım Neden Anlamını Yitiriyor?
- Gerçek zamanlı raporlama ve dashboard beklentisi
- AI modellerinin canlı üretim verisine ihtiyaç duyması
- Streaming ve event-driven mimarilerin yaygınlaşması
- Veri kopyalamadan sorgulama (zero-copy analytics) yaklaşımları
2026 veri altyapısı vizyonunda, veri artık “operasyonel” veya “analitik” olarak etiketlenmeden tek bir güvenilir kaynak üzerinden çok amaçlı kullanılmaktadır. Bu da veri formatlarını, bağlantı katmanlarını ve sorgu motorlarını stratejik hale getirmektedir.
Apache Arrow ve ADBC: Veri Bağlantısında Yeni Standartlar
Modern veri mimarisinin omurgası olan Apache Arrow, 2026 veri altyapısı tahminlerinin de temelini oluşturmaktadır. Arrow, verinin bellekte sütun bazlı ve standart bir biçimde temsil edilmesini sağlayarak, farklı sistemler arasında dönüşüm maliyetlerini ortadan kaldırır.

Apache Arrow Neden Bu Kadar Önemli?
- Sütun bazlı bellek düzeni sayesinde yüksek analitik performans
- Python, Java, C++, Rust gibi diller arasında ortak veri temsili
- Veri kopyalamadan paylaşım (zero-copy)
- CPU, GPU ve vektörleştirilmiş işlemler için uygun yapı
- Veri ekosisteminin ortak dili olarak görülmesi
ADBC (Arrow Database Connectivity) ile Ne Değişiyor?
ADBC, ODBC ve JDBC’nin modern alternatifidir. Arrow tabanlı bu bağlantı standardı sayesinde veri uygulamaya taşınmaz, uygulama veriye yaklaşır; analitik motorlar arası entegrasyon sadeleşir ve en önemlisi veri bilimi ve üretim sistemleri arasındaki bariyerler ortadan kalkar.
Açık Tablo Formatları: Apache Iceberg Neden 2026'nın Kazananı?
Apache Iceberg bugünlerde yalnızca teknik ekiplerin değil; CTO ve veri yöneticilerinin de gündeminde yer alan bir konu. Iceberg, veri gölü (data lake) esnekliğini; veri ambarı disiplinleriyle birleştiren açık bir tablo formatı olarak öne çıkar.
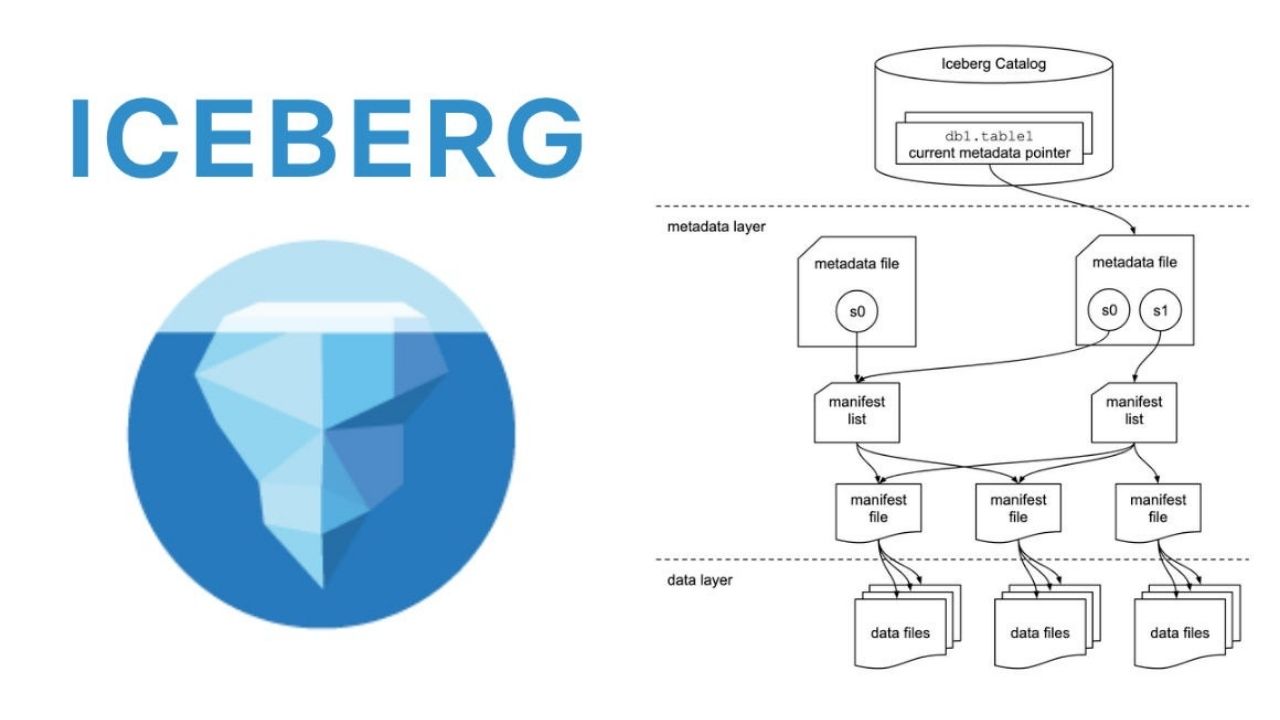
Iceberg’i Öne Çıkaran Temel Yetkinlikler
- ACID uyumlu tablo işlemleri
- Snapshot ve time travel desteği
- Şema evrimi ve geriye dönük uyumluluk
- Dosya seviyesinde ama tablo davranışında yap
- Parquet gibi dosya formatlarında yönetim ve güvenilir tablolar haline getirme
Vendor bağımlılığı olmadan ölçeklenebilir olması; Spark, Trino, Flink, DuckDB gibi çoklu motor desteği; gerçek zamanlı ve batch analitiği aynı zeminde buluşturması, 2026'da Iceberg’i açık tablo formatları arasında şimdiden ilk sıraya taşıyor.
DuckDB ve DataFusion: Monolitik Veri Ambarlarının Sonu
Geleneksel veri depoları; pahalı ve genellikle esnek olmayan sistemlerdi. Oysa veri ambarında yeni trendler, ihtiyaca göre ölçeklenen çözümlerin önemini ortaya koyuyor.
DuckDB, analitik sorguları doğrudan dosyalar üzerinde çalıştırabilen, sunucusuz bir sorgu motorudur:
- Kurulum gerektirmeden çalışır.
- Parquet ve Iceberg tablolarını doğrudan sorgular.
- Python, R ve veri bilimi araçlarıyla doğal uyumludur.
- Küçükten büyüğe ölçeklenebilir analitik sağlar.
- Veri ambarını bir servis olmaktan çıkarıp bir bileşen haline getirir.
Apache DataFusion, Arrow ekosistemi üzerine inşa edilmiş, yüksek performanslı bir sorgu motorudur:
- Rust tabanlıdır ve bellek güvenliği sağlar
- Embedded veya dağıtık mimarilerde çalışabilir
- Streaming ve AI iş yükleriyle uyumludur
DuckDB ve DataFusion göz önünde bulundurulduğunda monolitik veri ambarlarının yerini composable analytics yaklaşımının aldığı görülmektedir.
AI Ajanları İçin Tablo Verileri Neden Kritik Önemde?
2026’da yapay zeka sistemleri yalnızca metin üreten modeller olmayacak; veriyle etkileşime giren, karar alan ve aksiyon alan AI ajanları ön plana çıkacak. Bu ajanların başarısı, doğrudan veri altyapısının kalitesiyle ilişkili hale gelecek. Yapay zeka veri mimarisi, Iceberg tabloları ve Arrow bellek formatları üzerine kurulmakta. Gelecekte prompt mühendisliği değil, veri mühendisliği belirleyici rol oynayacak. Ayrıca açık standartlar, AI ölçeklenebilirliğinin ön koşulu olmaya devam edecek. 2026'da veri altyapısının kapalı ve monolitik değil açık ve modüler, tablo merkezli ama lake-native, yapay zeka ve analitiği aynı anda besleyen yapıya evrilmesi bekleniyor.
| 2026 Veri Trendi | Ana Odak Noktası | Beklenen Etki |
| Apache Iceberg | Açık Tablo Formatları | Standartlaşma ve Üretim Başarısı |
| Multi-Engine Stack | Storage ve Compute Ayrımı | Maliyet Tasarrufu ve Esneklik |
| AI Ajan Entegrasyonu | Yapılandırılmış (Tabular) Veri | Hızlı ve Güvenli Veri Erişimi |
| ADBC Standartları | Veri Bağlantı Katmanı | Eski ODBC/JDBC Sistemlerinin Değişimi |
Yorumlar (0)
Yorum yapmak için giriş yapmalısınız.
Giriş Yap